
目录
Table of Contents
从顶层结构图入手
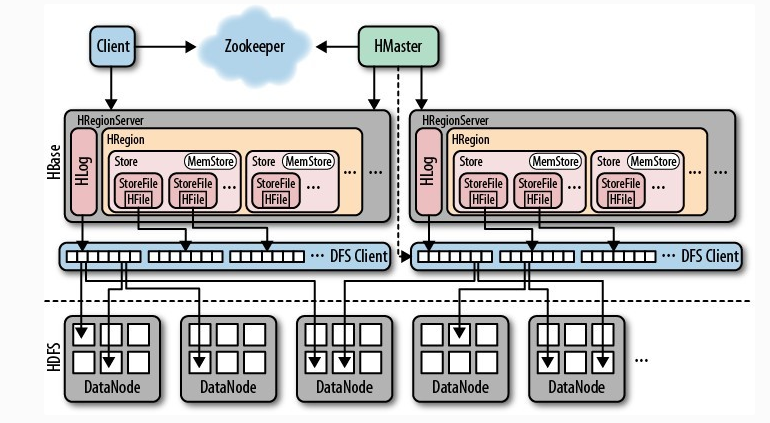
上图展示了Hbase是如何与Hadoop文件系统协作完成数据存储的,从这张图可以看出Hbase主要处理两种文件
- 预写日志(Write-Ahead Log)
- 实际的数据文件
这两种文件由HRegionServer管理。下面简述一次查找过程:
- Hbase Client首先联系Zookeeper集群(quorum)查找行键。Zookeeper会返回-ROOT-的region服务器名,通过这个信息查询.META.表中对应的region服务器名和行信息,此信息会被Client缓存下来
- Client根据根据上一步的结果直接联系管理实际数据的HRegionServer
- HRegionServer负责打开region,并创建对应的HRegion实例。HRegion被打开后,它会为每个表的HColumnFamily创建一个Store实例,每个Store实例包含一个或者多个StoreFile实例,他们是实际存储文件HFile的轻量级封装。每个Store对应一个MemStore,一个HRegionServer共享一个HLog实例
文件
根级文件
WAL文件
这些文件被创建在HBase的根目录下一个名为WALS的目录下。对于每个HRegionServer,日志目录中都包含一个对应的子目录,在每个子目录中有多个HLog文件。一个HRegionServer的所有region共享同一组HLog文件。
当所有的包含的修改都被持久化到存储文件中,从而不再需要日志文件时,它们会被放到Hbase的根目录下的oldWALS目录中,在10分钟(默认情况下)后,旧的日志文件将被master删除。
hbase.id和hbase.version
这两个文件分别包含集群的唯一ID和文件格式版本信息
表级文件
每张表都有自己的记录,每个表都对应hdfs中的一个目录。路径为: /hbase/data/{namespace}/{tablename}。
Hbase的每个表都从属一个命名空间,没有指定命名空间的表默认为default
region级文件
在表级目录下一层级,是region对应的文件夹,文件名就是region名。region文件的总体结构是:
/hbase/data/{namespace}/{tablename}/{regionname}/{column-family}/filename。
用户可以在每个列族目录中看到实际的数据文件。这些文件仅仅是一个随机生成的数。代码能够智能地检查出发生的碰撞,即新生成号码对应的文件以及存在,程序将一直循环,知道找到一个未使用的数字。
region拆分
一旦region超过了配置中的region大小的最大值,region就需要拆分。这个过程通常非常迅速,因为系统只是为新region创建了两个对应的文件,每个region是原始region的一半。
regionServer通过在父region中创建splits目录来完成这个过程。接下来关闭该region,此后这个region不在接受任何请求。如果这个过程成功,它会把两个新的region目录迁移到表目录中,同时.META.表中父region的状态会被更新。
HFile格式
实际的存储文件功能是由HFile实现的,它被专门创建以达到一个目的:有效地存储Hbase的数据。
从HBase开始到现在,HFile经历了三个版本,其中V2在0.92引入,V3在0.98引入。HFileV1版本的在实际使用过程中发现它占用内存多,HFile V2版本针对此进行了优化,HFile V3版本基本和V2版本相同,只是在cell层面添加了Tag数组的支持。

上图对应的v2的逻辑结构,文件主要分为四个部分:
-
Scanned block section
顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block
-
Non-scanned block section
在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分
-
Load-on-open-section
这部分数据在Hbase region server启动时,需要加载到内存中,包括FileInfo、Bloom filter block、data block index和meta block index
-
Trailer
主要记录了HFile的基本信息、各个部分的偏移值和寻址信息
HFile会被切分为多个大小相等的block块,block块都拥有相同的数据结构,每个block的大小可以在创建表列簇的时候通过参数blocksize => ‘65535’进行指定,默认为64k。大号block有利于顺序Scan,小号Block有利于随机查询,因而需要权衡。V2相比V1有如下特点:
-
分层索引
Data Block的索引,在HFile V2中做多可支持三层索引:最底层的Data Block Index称之为Leaf Index Block,可直接索引到Data Block;中间层称之为Intermediate Index Block,最上层称之为Root Data Index,Root Data index存放在一个称之为”Load-on-open Section“区域,Region Open时会被加载到内存中。基本的索引逻辑为:由Root Data Index索引到Intermediate Block Index,再由Intermediate Block Index索引到Leaf Index Block,最后由Leaf Index Block查找到对应的Data Block。在实际场景中,Intermediate Block Index基本上不会存在,因此,索引逻辑被简化为:由Root Data Index直接索引到Leaf Index Block,再由Leaf Index Block查找到的对应的Data Block。
Bloom Filter也被拆成了多个Bloom Block,在”Load-on-open Section”区域中,同样存放了所有Bloom Block的索引数据。
-
交叉存放
在”Scanned Block Section“区域,Data Block(存放用户数据KeyValue)、存放Data Block索引的Leaf Index Block(存放Data Block的索引)与Bloom Block(Bloom Filter数据)交叉存在。
-
按需读取
无论是Data Block的索引数据,还是Bloom Filter数据,都被拆成了多个Block,基于这样的设计,无论是索引数据,还是Bloom Filter,都可以按需读取,避免在Region Open阶段或读取阶段一次读入大量的数据,有效降低时延。
KeyValue格式
本质上,HFile中的每个KeyValue都是一个低级的字节数组,它允许零复制访问数据。
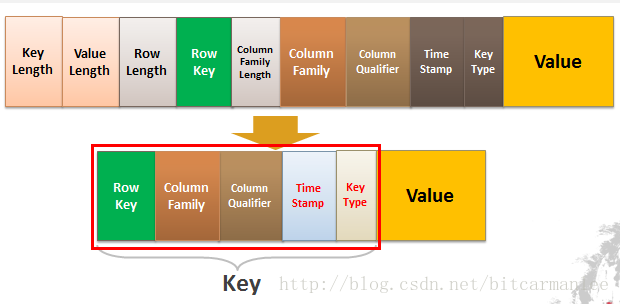
该结构以两个分表表示键长度和值长度的定长数字开始。有了这个信息,用户就可以在数据中跳跃,例如,可以忽略键直接访问值。一旦其被转换成一个KeyValue的Java实例,用户就能通过对应的Getter方法得到更多的细节信息。
从KeyValue的结构来看,每条记录都存储了对应的rowkey的值,因此在实际开发中,rowkey的长度要仔细设计,以免造成的开销。