
目录
Table of Contents
Apache Spark is a unified analytics engine for large-scale data processing.
$Features$
-
Speed
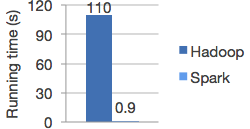
Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
-
Ease of Use
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
-
Generalily
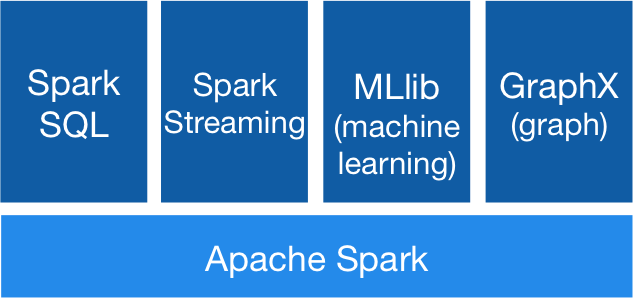
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
-
Runs Everywhere
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
以上摘自http://spark.apache.org/,描述了Apache Spark是一个用于大规模数据处理的统一分析引擎,并讲述了spark具有速度、易用、通用性和可融合性的特性。
Spark的目标是为了基于工作集的应用提供抽象,同时保持MapReduce及其相关模型的优势特性,即自动容错、位置感知性调度和可伸缩性。下面会根据各个spark-core各个模块进行分析,来描述spark是怎么达到这些特性的。
Spark架构综述
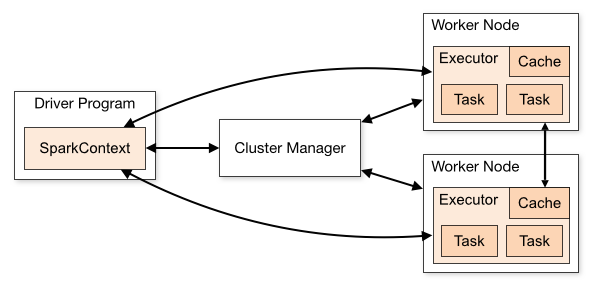
spark整体架构如图。其中Driver是用户编写的数据处理逻辑,这个逻辑中包含用户创建的SparkContext。SparkContext是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager交互,包括向Cluster Manager申请计算资源。Cluster Manager负责集群的资源管理和调度。Executor是在一个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。Task是被送到某个Executor上的计算单元。
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
- 用户程序创建SparkContext时,新创建的SparkContext实例会连接到ClusterManager。ClusterManager会根据用户提交时设置的CPU和内存等信息为本次提交分配计算资源,启动Executor。
- Driver会将用户程序划分不同的执行阶段,每个执行阶段由一组完全相同的Task组成,这些Task分表作用域待处理数据的不同分区。在阶段划分完成和Task创建后,Driver会向Executor发送Task。
- Executor在接受到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver。
- Driver会根据收到的Task的运行状态来处理不同的状态更新。
- Driver会不断调用Task,将Task发送到Executor执行,将所有的Task都正确执行或者执行次数的限制任然没有执行成功停止。
RDD
RDD是Spark最基本的也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,RDD提供了一种高度受限的共享内存,即RDD是只读的,并且只能通过其他RDD上的批量操作来创建。
一般来说,分布式数据集的容错性有两种方式:数据检查点和记录数据的更新。面向大规模数据分析,数据检查点操作成本很高;但是记录数据更新,更新太多,记录更新成本也不低。因此RDD只支持粗粒度转换,即在大量记录上执行单个操作。将创建RDD的一系列转换记录下来(即Lineage),以便恢复丢失的分区。
每个RDD有5个主要的属性:
- 一组分片(partition),即数据集的基本组成单位。对于RDD来说,每个partition都会被一个计算任务处理,并决定计算的力度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值(程序分配到的CPU的core的数目)。
- 一个计算每个分区的函数。每个RDD都会实现compute函数以达到分片的目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
- RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对所有的RDD的所有分区进行重新计算。
- 一个Partitioner,即RDD的分片函数。只有key-value的RDD才会有Partitioner,非key-value的RDD的partitioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDDShuffle输出时的分片数量。
- 一个列表,存取每个Partiton的优先位置(preferredLocations)。对于一个HDFS文件来说,这个列表保存的就是每个partition所在的块的位置。按照移动数据不如移动计算的理念,Spark在进行任务调度的时候,会尽可能将计算任务分配到其索要处理数据块的存储位置。
RDD的创建
可以通过两种方式创建RDD:
- 由一个已存在的Scala集合创建
- 由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,如HDFS、Hbase。
RDD的转换
RDD中的所有转换都是惰性的。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。
Transformations
| Transformation | Meaning |
|---|---|
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which funcreturns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so funcshould return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | Return a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process’s stdin and lines output to its stdout are returned as an RDD of strings. |
| coalesce(numPartitions) | Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| repartitionAndSortWithinPartitions(partitioner) | Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
Actions
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) | Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop’s Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (Java and Scala) | Write the elements of the dataset in a simple format using Java serialization, which can then be loaded usingSparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
RDD缓存
当持久化一个RDD后,每一个节点都将把计算的分片结果保存在分片中,并在对此数据集进行其他的动作中重用。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除。RDD缓存的容错机制保证了即使缓存丢失也能保证计算的正确执行。通过RDD的一系列转换,丢失的数据会被重算。RDD的各个partition是相对独立的,因此只需要计算丢失的部分即可。
Spark的存储级别意味着在内存使用和CPU效率之间提供不同的权衡,通过以下步骤选择一个存储级别:
- 如果RDD与内存匹配的很好,那就保持这种状态,这是最高效的cpu选项,允许RDD上的操作尽可能快的运行;
- 如果没有,尝试只使用内存并选择一个快速序列化库,以使对象更节省空间,但访问速度仍然相当快。
- 不要溢出到磁盘,除非计算数据集的函数非常昂贵,或者它们过滤了大量数据。否则,重新计算分区的速度可能与从磁盘读取分区一样快。
- 如果希望快速的故障恢复的话,可以使用混合的存储的级别。所有的存储级别都通过重复计算丢失的数据提供了容错性。但是混合的存储级可以继续运行task而不需要重复计算丢失的分区。
RDD检查点
通过缓存,Spark避免了RDD上的重复计算,为了避免缓存丢失重新计算带来的开销,spark又引入了检查点(checkpoint)机制。针对特复杂或者计算耗时特别多的应用而言,有极大的好处。
RDD的转换和DAG的生成
Spark会根据用户提供的Application的计算逻辑中的RDD的transform和action来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG。
RDD依赖关系
RDD之间的关系可以从两个维度来理解:
- RDD从哪些RDD转换而来,也就是parent RDDs是什么
- 依赖于parent RDDs的那些Partitons
RDD和parent RDDs的关系分为窄依赖和宽依赖。
- 窄依赖: 每一个parent RDD的Partiton最多被子RDD的一个Partition使用
- 宽依赖: 多个字RDD的Partition会依赖同一个parent RDD的Partiton
DAG的生成
RDD的依赖关系是DAG的重要属性,借助这些依赖关系,DAG可以认为这些RDD之间形成了Lineage(血统)。借助Lineage,能保证一个RDD被计算钱,它所依赖的parentRDD都已经完成了计算;同时也实现了RDD的容错性。
$根据DAG生成任务$
根据依赖关系的不同将DAG划分为不同的阶段。
- 对于窄依赖,由于Partition依赖关系的确定性,Partition的转换处理就可以在同一个线程里完成,窄依赖被Spark划分到通一个执行阶段
- 对于宽依赖,由于shuffle的存在,只能在parent RDDs处理完成后,才能开始接下来的计算,因此宽依赖是spark的划分依据,即Spark根据宽依赖将DAG划分为不同的Stage。
RDD的计算
TASK
原始RDD经过转换后,会在最后一个RDD上出发一个动作,这个动作会生成一个Job。在Job被划分为一匹计算任务(Task)后,这批Task会被提交到集群上的计算节点去计算。执行Task计算逻辑的是Executor,Executor在准备好Task的运行环境后,会通过调用org.apache.spark.scheduler.Task#Run来执行计算。Spark的Task分为两种:
ShuffleMapTaskResultTask
Dag最后一个阶段会为每个结果的Partiton生成一个ResultTask,其余所有的阶段都会生成ShuffleMapTask。
Task的执行起点
-
org.apache.spark.scheduler.Task#Run会调用ShuffleMapTask或ResultTask的runTask; -
runTask会调用
org.apache.spark.rdd.RDD#iterator方法计算由此产生/** * Internal method to this RDD; will read from cache if applicable, or otherwise compute it. * This should ''not'' be called by users directly, but is available for implementors of custom * subclasses of RDD. */ final def iterator(split: Partition, context: TaskContext): Iterator[T] = { if (storageLevel != StorageLevel.NONE) { getOrCompute(split, context) } else { computeOrReadCheckpoint(split, context) } } -
RDD的计算逻辑在
org.apache.spark.rdd.RDD#compute中实现Scheduler模块
Scheduler(任务调度)模块作为Spark Core的核心模块之一,充分体现了MapReduce完全不同的设计思想。
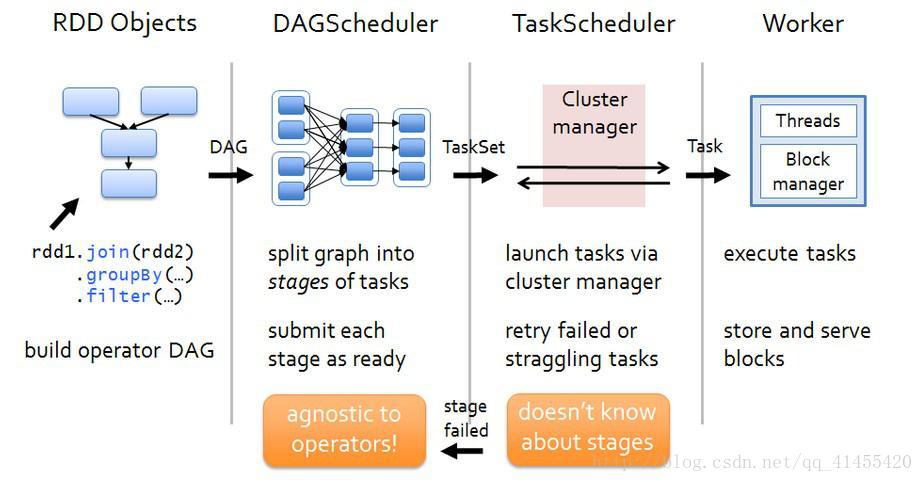
任务调度模块主要包括两大部分,即DAGScheduler和TaskScheduler,负责将用户提交的Application按照DAG划分为不同的阶段,并且将不同阶段的计算任务提交到集群进行最终的计算。整个过程如上图所示,描述如下:
- RDD Objects理解为用户实际代码中创建的RDD,这些代理逻辑上组成了一个DAG,支持复杂拓扑
- DAGScheduler主要分析用户提交的应用,并根据计算任务的依赖关系建立DAG,然后将DAG划分为不同stage(阶段)。每个Stage由可以并发执行的一组Task构成,这些Task的执行逻辑完全相同,只是作用于不同的数据。
- DAGScheduler将Task划分完后,会将这组Task提交到TaskScheduler;TaskScheduler通过Cluster Manager在集群中的某个Worker的Executor上启动任务。同时计算的结果会回传到Driver或者保存到本地。
DAGScheduler实现
DAG的创建
DAGScheduler和TaskScheduler都是在SparkContext创建的时候创建的,DAGScheduler的构造函数:
private[spark]
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
}
MapOutputTrackerMaster是运行在Driver端管理Shuffle Map Task的输出的,下游的Taskk可以通过MapOutputTrackerMaster来获取Shuffle输出的位置信息。BlockManagerMaster也是运行在Driver端的,它管理整个Job的Block的信息。
Job的提交
用户提交的Job最终会调用DAGSchedule#runJob,它会调用DAGSchedule#submitJob,
/**
* Submit an action job to the scheduler.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like first()
* @param callSite where in the user program this job was called
* @param resultHandler callback to pass each result to
* @param properties scheduler properties to attach to this job, e.g. fair scheduler pool name
*
* @return a JobWaiter object that can be used to block until the job finishes executing
* or can be used to cancel the job.
*
* @throws IllegalArgumentException when partitions ids are illegal
*/
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
- submitJob会为Job生成一个JobID,并且生成一个JobWaiter的实例,来监听Job的执行情况
- 最后DagScheduler会向eventProcessLoop提交该Job,eventProcessLoop是一个异步的操作,最终会调用
DAGScheduler.handleJobSubmitted来处理这次提交
Stage的划分
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
DAGScheduler.handleJobSubmitted首先根据RDD创建finalStage。finalStage就是最后的Stage。
RDD在转换的时候需要做Shuffle,那么这个Shuffle的过程就讲这个DAG分为了不同的阶段(即Stage)。
$划分依据$
RDD之间的依赖关系:宽依赖和窄依赖
$划分过程$
finalStage创建过程中会调用DAGScheduler.getOrCreateParentStages获取parentStages。
任务的生成
生成finalJob后,会为该Job生成一个org.apache.spark.scheduler.ActiveJob,并准备计算这个finalStage;
通过调用DAGScheduler.submitStage方法来提交这个Stage,如果他的某些parentStage没有提交,那么递归提交那些未提交的(或者未计算的)parentStage,只有所有的parentStage都计算完成后,才能提交它。
DAGScheduler.submitMissingTasks会完成最后的工作,向TaskScheduler提交Task。提交前会为每个Partition生成Task,然后这些Tasks会被封装到org.apache.spark.scheduler.TaskSet,然后提交到TaskScheduler。
/**
* A set of tasks submitted together to the low-level TaskScheduler, usually representing
* missing partitions of a particular stage.
*/
private[spark] class TaskSet(
val tasks: Array[Task[_]],
val stageId: Int,
val stageAttemptId: Int,
val priority: Int,
val properties: Properties) {
val id: String = stageId + "." + stageAttemptId
override def toString: String = "TaskSet " + id
}
至此,DAGScheduler就完成了它的使命,然后它会等待TaskScheduler,最终向集群提交这些Task,监听这些Taks的状态。
任务调度的实现
每个TaskScheduler都对应一个SchedulerBackend。其中TaskScheduler负责Application的不同Job之间的调度,在Task执行失败时启动重试机制,并且为执行速度慢的Task启动备份任务。而SchedulerBackend负责与ClusterManager交互,取得该APP理财通分配的资源,并且将这些资源传给TaskScheduler,由TaskScheduler为Task最终分配计算资源。
TaskScheduler的创建
前面讲到TaskScheduler是由SparkContent#createTaskScheduler创建的。该方法会根据传入的Master的URI的规则判断集群的资源管理的方式(Standalone、Mesos、YARN或者是Local)。根据通的方式生成不同TaskScheduler和SchedulerBackend。SchedulerBackend使用reviveOffers方法完成上述的任务调度。
TaskScheduler提交
DAGScheduler完成了对Stage的解析后,会按照顺序将Stage通过org.apache.spark.scheduler.TaskScheduler#submitTasks提交;submitTasks开始Task级别的资源调度。
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
任务调度
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
schedulableBuilder有两种实现方式:
org.apache.spark.scheduler.FIFOSchedulableBuilderorg.apache.spark.scheduler.FairSchedulableBuilder
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
-
FIFO调度
首先要保证JobID较小的先被调度,如果是同一个Job,那么StageID小的先被调度,同一个Job,可能多个Stage可以并行执行。
-
FAIR调度
对于FAIR,它需要在rootPool的基础上根据配置文件来构建这颗调度树。对于FAIR,首先是挂到rootPool下面的pool先确定调度顺序,然后在每个pool内部使用相同的算法来确定TaskSetManager的调度顺序。
将Task发送到Executor
backend.reviveOffers()
Task运算结果的处理
-
Driver收到Executor的任务执行结果,实现逻辑在
TaskSchedulerImpl#statusUpdatedef statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) { var failedExecutor: Option[String] = None var reason: Option[ExecutorLossReason] = None synchronized { try { taskIdToTaskSetManager.get(tid) match { case Some(taskSet) => if (state == TaskState.LOST) { // TaskState.LOST is only used by the deprecated Mesos fine-grained scheduling mode, // where each executor corresponds to a single task, so mark the executor as failed. val execId = taskIdToExecutorId.getOrElse(tid, throw new IllegalStateException( "taskIdToTaskSetManager.contains(tid) <=> taskIdToExecutorId.contains(tid)")) if (executorIdToRunningTaskIds.contains(execId)) { reason = Some( SlaveLost(s"Task $tid was lost, so marking the executor as lost as well.")) removeExecutor(execId, reason.get) failedExecutor = Some(execId) } } if (TaskState.isFinished(state)) { cleanupTaskState(tid) taskSet.removeRunningTask(tid) if (state == TaskState.FINISHED) { taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData) } else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) { taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData) } } case None => logError( ("Ignoring update with state %s for TID %s because its task set is gone (this is " + "likely the result of receiving duplicate task finished status updates) or its " + "executor has been marked as failed.") .format(state, tid)) } } catch { case e: Exception => logError("Exception in statusUpdate", e) } } // Update the DAGScheduler without holding a lock on this, since that can deadlock if (failedExecutor.isDefined) { assert(reason.isDefined) dagScheduler.executorLost(failedExecutor.get, reason.get) backend.reviveOffers() } }一个Task的状态只有
TaskState.FINISHED才标记为成功执行,其余都是执行是执行失败。Excutor在将结果回传到Driver时,会根据结果的大小使用不同的策略:
- 如果结果大于1G,那么直接丢弃这个结果
- 对于较大的结果,将其以tid为key存入org.apache.spark.storage.BlockManager;如果结果不大,则直接回传Driver。这个阈值是AKKA的消息传递机制限定的。
-
处理任务成功执行的机制
def enqueueSuccessfulTask( taskSetManager: TaskSetManager, tid: Long, serializedData: ByteBuffer): Unit = { getTaskResultExecutor.execute(new Runnable { override def run(): Unit = Utils.logUncaughtExceptions { try { val (result, size) = serializer.get().deserialize[TaskResult[_]](serializedData) match { case directResult: DirectTaskResult[_] => if (!taskSetManager.canFetchMoreResults(serializedData.limit())) { return } // deserialize "value" without holding any lock so that it won't block other threads. // We should call it here, so that when it's called again in // "TaskSetManager.handleSuccessfulTask", it does not need to deserialize the value. directResult.value(taskResultSerializer.get()) (directResult, serializedData.limit()) case IndirectTaskResult(blockId, size) => if (!taskSetManager.canFetchMoreResults(size)) { // dropped by executor if size is larger than maxResultSize sparkEnv.blockManager.master.removeBlock(blockId) return } logDebug("Fetching indirect task result for TID %s".format(tid)) scheduler.handleTaskGettingResult(taskSetManager, tid) val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId) if (!serializedTaskResult.isDefined) { /* We won't be able to get the task result if the machine that ran the task failed * between when the task ended and when we tried to fetch the result, or if the * block manager had to flush the result. */ scheduler.handleFailedTask( taskSetManager, tid, TaskState.FINISHED, TaskResultLost) return } val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]]( serializedTaskResult.get.toByteBuffer) // force deserialization of referenced value deserializedResult.value(taskResultSerializer.get()) sparkEnv.blockManager.master.removeBlock(blockId) (deserializedResult, size) } // Set the task result size in the accumulator updates received from the executors. // We need to do this here on the driver because if we did this on the executors then // we would have to serialize the result again after updating the size. result.accumUpdates = result.accumUpdates.map { a => if (a.name == Some(InternalAccumulator.RESULT_SIZE)) { val acc = a.asInstanceOf[LongAccumulator] assert(acc.sum == 0L, "task result size should not have been set on the executors") acc.setValue(size.toLong) acc } else { a } } scheduler.handleSuccessfulTask(taskSetManager, tid, result) } catch { case cnf: ClassNotFoundException => val loader = Thread.currentThread.getContextClassLoader taskSetManager.abort("ClassNotFound with classloader: " + loader) // Matching NonFatal so we don't catch the ControlThrowable from the "return" above. case NonFatal(ex) => logError("Exception while getting task result", ex) taskSetManager.abort("Exception while getting task result: %s".format(ex)) } } }) }
Deploy模块
Spark的ClusterManager有以下几种部署方式:Standalone、Mesos、YARN、EC2、Local。不同运行模式实际上是实现了不同的SchedulerBackend和TaskScheduler
-
local
本地方式启动spark
- local:使用一个工作线程来运行计算任务,不会重新计算失败的计算任务
- local[N]: local[N]是使用N个线程,不会重新计算失败的计算任务
- local[*]: 工作线程的数量取决于本机的CPU Core的数目,不会重新计算失败的计算任务
- local[thread, maxFailures]: threads设置了工作线程的数目;maxFailures设置了计算任务最大失败重试次数
- Local-cluster[numSlaves, coresPerSlave, memoryPerSlave]: 伪分布式模式,本机会运行Master和Worker。numSlaves设置Worker的数目;coresPerSlave设置Worker所能使用CPU Core的数目;memoryPerSlave设置每个Worker所能使用的内存数
Local-cluster除了MasterWorker都运行在本机外,与Standalone模式并无区别。
-
YARN

- ResourceManager(资源管理器)全局管理所有应用程序计算资源的分配。它和每一台机器的NodeManager(节点管理器)能够管理应用在那台机器上的进程并能对计算进行组织。ResourceManager基于应用程序对资源的需求进行调度,资源包括:
- 内存
- CPU
- 硬盘
- 网络等
- 每一个应用的ApplicationMaster则负责相应的调度和协调。ApplicationMaster从ResourceManager获得资源和NodeManager协同工作来运行和监控任务。ApplicationMaster的职责如下:
- 向ResourceManager索要适当的资源容器
- 运行任务
- 跟踪应用程序的状态和监控他们的进程
- 处理任务的失败原因
- NodeManager是每一台机器框架的代理,是执行应用程序的容器,监控应用的资源使用情况(CPU、内存、硬盘、网络),并且向调度器汇报
- Client提交Job后,ApplicationMaster向ResourceManager请求资源,在获得资源后,ApplicationMaster会在NodeManager上启动Container,运行计算任务,并且和Container保持联系,监控任务的运行状态等
- ResourceManager(资源管理器)全局管理所有应用程序计算资源的分配。它和每一台机器的NodeManager(节点管理器)能够管理应用在那台机器上的进程并能对计算进行组织。ResourceManager基于应用程序对资源的需求进行调度,资源包括:
模块整体架构
Deploy模块采用的也是典型的Master/Slave架构。
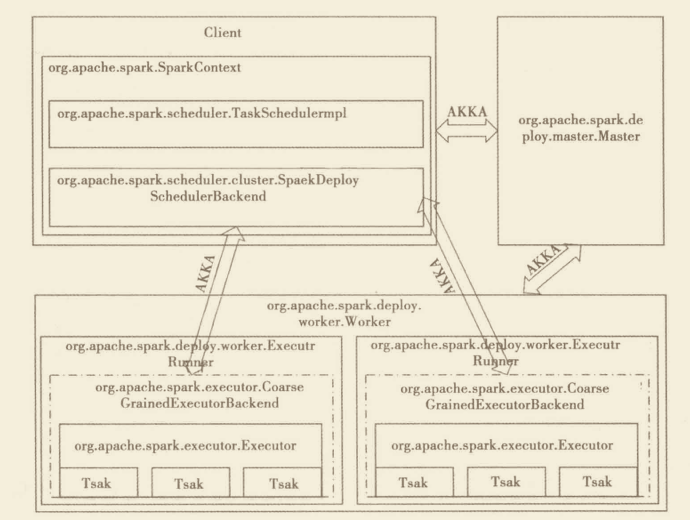
Deploy模块主要包含3个子模块:Master、Worker、Client,他们之间通信通过AKKA完成。
- Master:接受Worker的注册并管理所有的Worker;接受Client提交的Application,FIFO调度等待的Application并向Worker提交。
- Worker:向Master注册自己,根据Master发送的Application配置进程环境,并启动StandaloneExecutorBackend
- Client:向Master注册并监控Application。当用户创建SparkContext时会实例化SparkDeploySchedulerBackend,同时会启动Client,通过Client传递启动参数和Application有关信息。
集群的启动
Spark集群部署完成后,启动整个集群会发生什么?
Master的启动
Master的实现是org.apache.spark.deploy.master.Master,一个机器可以部署多个Master,以达到高可用的目的,因此它还实现了org.apache.spark.deploy.master.LeaderElectable以在多个Master中选举一个Leader。
Master保持了整个集群的元数据,包括Worker、Application和Driver Client。Spark的Standalone模式支持一下几种元数据的持久化方式和选举方式:
- Zookeeper: 基于Zookeeper的选举机制,元数据信息会持久化到Zookeeper中
- FileSystem: 元信息保存到本地文件系统
- Custom:用户自定义,需要实现
org.apache.spark.deploy.master.StandaloneRecoveryModeFactory - None: 不持久化集群的元数据,Master在启动后会立即接管集群的管理工作
被选举为Leader的Master,会首先读取集群的元数据信息,如果有读到的数据,那么Master的状态就会变为RecoveryState.RECOVERING,然后开始恢复数据和通知Worker、AppClient和DriverClient,Master已经更改,恢复结束后Master的状态变为RecoveryState.ALIVE。Master只有在状态是RecoveryState.ALIVE时才可以对外服务。
Worker的启动
Worker的启动只做向Master注册这一件事情。
Worker注册会收到Master的消息,成功则结束,失败则重试。重试机制为在指定时间如果收不到Master的响应,那么Worker会重新发送注册请求,目前次数最多为16次。
注册成功后,Worker就可以对外服务了,即接受Master的指令。
集群容错处理
对于一个集群来说,机器故障、网络故障灯都被视为常态,尤其是当集群达到一定规模后,可能每天都会有物理故障导致某台机器不能提供服务。因此从Master、Worker和Executor的异常退出出发,讨论Spark是如何处理的。
Master异常退出
Master异常退出,此时新的计算任务就无法进行提交,正在计算的任务状态更新中断,计算任务完成后的资源回收无法进行。
在这种情况下,Zookeeper会在备份的Master中选择一个充当集群的管理者。新选出来的Master会从Zookeeper中读取集群的元数据进行数据恢复。然后告知Worker和AppClient,Master已经更改的消息。在收到所有的Worker和AppClient的响应或者超时后,Master就会变成ACTIVE的状态,并开始对外提供服务。
Worker的异常退出
Worker的异常退出发生概率非常高。Worker容错处理如下:
- Worker在退出钱,将所有运行在它上面的Executor和DriverClient删除
- Worker维持Master的周期心跳,Worker退出后心跳超时,Master人为Worker异常退出。Master会将该Worker上运行的所有的Executor的状态标记为丢失。然后将这个状态更新通知AppClient;该Worker上运行的DriverClient如果它设置了需要重启,那么需要重新调度来重启DriverClient,否则直接删除,并且将状态设置为DriverState.ERROR。
Executor的异常退出
Executor退出后,汇报Worker,Worker会将这个消息转发到Master。Master将会为该Application分配新的Executor。如果超过10次,那么将会这个Application标记为失败。
Executor模块
Standalone模式Executor分配详解
AppClient的创建
org.apache.spark.scheduler.cluster.StandaloneSchedulerBackend#start中创建AppClient,而AppClient可以向Master注册Application
override def start() {
super.start()
// SPARK-21159. The scheduler backend should only try to connect to the launcher when in client
// mode. In cluster mode, the code that submits the application to the Master needs to connect
// to the launcher instead.
if (sc.deployMode == "client") {
launcherBackend.connect()
}
// The endpoint for executors to talk to us
val driverUrl = RpcEndpointAddress(
sc.conf.get("spark.driver.host"),
sc.conf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "",
"--hostname", "",
"--cores", "",
"--app-id", "",
"--worker-url", "")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val webUrl = sc.ui.map(_.webUrl).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
// If we're using dynamic allocation, set our initial executor limit to 0 for now.
// ExecutorAllocationManager will send the real initial limit to the Master later.
val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
AppClient向Master注册Application
AppClient是Application向Maste交互的接口。StandaloneAppClient包含了ClientEndpoint#receive,它负责所有与Master的交互,主要交互如下:
override def receive: PartialFunction[Any, Unit] = {
case RegisteredApplication(appId_, masterRef) =>
// FIXME How to handle the following cases?
// 1. A master receives multiple registrations and sends back multiple
// RegisteredApplications due to an unstable network.
// 2. Receive multiple RegisteredApplication from different masters because the master is
// changing.
appId.set(appId_)
registered.set(true)
master = Some(masterRef)
listener.connected(appId.get)
case ApplicationRemoved(message) =>
markDead("Master removed our application: %s".format(message))
stop()
case ExecutorAdded(id: Int, workerId: String, hostPort: String, cores: Int, memory: Int) =>
val fullId = appId + "/" + id
logInfo("Executor added: %s on %s (%s) with %d core(s)".format(fullId, workerId, hostPort,
cores))
listener.executorAdded(fullId, workerId, hostPort, cores, memory)
case ExecutorUpdated(id, state, message, exitStatus, workerLost) =>
val fullId = appId + "/" + id
val messageText = message.map(s => " (" + s + ")").getOrElse("")
logInfo("Executor updated: %s is now %s%s".format(fullId, state, messageText))
if (ExecutorState.isFinished(state)) {
listener.executorRemoved(fullId, message.getOrElse(""), exitStatus, workerLost)
}
case WorkerRemoved(id, host, message) =>
logInfo("Master removed worker %s: %s".format(id, message))
listener.workerRemoved(id, host, message)
case MasterChanged(masterRef, masterWebUiUrl) =>
logInfo("Master has changed, new master is at " + masterRef.address.toSparkURL)
master = Some(masterRef)
alreadyDisconnected = false
masterRef.send(MasterChangeAcknowledged(appId.get))
}
Master在收到注册请求后,执行org.apache.spark.deploy.master.Master#receive方法的如下代码:
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()
}
在调用Master的PersistenceEngine持久化Application的元数据后,会将结果返回AppClient;之后会开始新一轮的资源调度Master#schedule。除了新加入的Application会开始资源调度外,资源的本身变动,比如Worker的加入,也会开始资源调度。
Master根据AppClient的提交选择Worker
Master#schedule为处于待分配资源的Application分配资源。为Application分配资源选择Worker有2中策略:
- 尽量打散,即将一个Application尽可能多地分配打不通的接点。
- 尽量集中,即将一个Application尽量分配到尽可能少的节点。CPU密集型而内存占用比较少的Application适合使用这种策略。
Worker根据Master的资源分配结果创建Executor
org.apache.spark.deploy.worker.Worker接收到Master的launchExecutor后,会创建ExecutorRunner,代码org.apache.spark.deploy.worker.Worker#receive->launchExecutor如下:
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// Create the executor's working directory
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Create local dirs for the executor. These are passed to the executor via the
// SPARK_EXECUTOR_DIRS environment variable, and deleted by the Worker when the
// application finishes.
val appLocalDirs = appDirectories.getOrElse(appId, {
val localRootDirs = Utils.getOrCreateLocalRootDirs(conf)
val dirs = localRootDirs.flatMap { dir =>
try {
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
Some(appDir.getAbsolutePath())
} catch {
case e: IOException =>
logWarning(s"${e.getMessage}. Ignoring this directory.")
None
}
}.toSeq
if (dirs.isEmpty) {
throw new IOException("No subfolder can be created in " +
s"${localRootDirs.mkString(",")}.")
}
dirs
})
appDirectories(appId) = appLocalDirs
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {
case e: Exception =>
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}
ExecutorRunner将准备好的ApplicationDescription以进程的形式启动。
Shuffle模块
Shuffle,无疑是性能调优的一个重点,翻译成中文就是洗牌。之所以需要Shuffle,还是因为具有某种共同特征的一类数据需要最终汇聚(aggreagte)到一个计算节点上进行计算。这些数据分布在各个存储节点上并且由不同节点的计算单元处理。
数据重新打乱后汇聚到不同节点的过程就是Shuffle。但是实际上,Shuffle的过程可能非常复杂:
- 数据量会很大
- 为了将这个数据汇聚到正确的节点,需要将这些数据放入正确的Partiton,因为数据大小已经大于节点的内存,因此这个过程中可能会发生多次硬盘续写
- 为了节省带宽,这个数据可能需要压缩,如何在压缩率和压缩、解压时间中间做一个比较好的选择?
- 数据通过网络传输,因此数据的序列化和反序列化也变得相对复杂
Shuffle中间数据持久化
一般来说,每个Task处理的数据可以完全载入内存(如果不能,可以减小每个Partiton的大小),因此Task可以做到在内存中计算。除非非常复杂的计算逻辑,否则为了容错而持久化中间的数据是没有太大收益的,毕竟中间某个过程出错了可以从头开始计算。但是对于Shuffle来说,如果不持久化这个中间结果,一旦数据丢失,就需要重新计算依赖的全部RDD,因此有必要持久化这个中间结果。
接下来会分析每个Shuffle Map Task结束时,数据是如何持久化(即Shuffle Write)以使得下游的Task可以获取到其需要处理的数据的(Shuffle Read)。
Hash Based Shuffle Write
在Spark1.0以前,Spark只支持Hash Based Shuffle。
Spark的实现是每个Shuffle Map Task根据Key的哈希值,计算出每个key需要写入的Partiton,然后将数据单独写入一个文件,这个Partiton实际上就对应了一个下游的一个Shuffle Map Task或者Result Task。因此下游的Task会在计算时通过网络读取这个文件,并进行计算(如果下游Task与上游Shuffle Map Task运行在同一个节点上,那么此时就是一个本地的硬盘读写)。
Basic Shuffle Writer实现
在Executor上执行Shuffle Map Task时,最终会调用org.apache.spark.scheduler.ShuffleMapTask#runTask,核心逻辑:
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
- 从SparkEnv获得shuffleManager;Spark除了支持Hash和Sort Based Shuffle外,还支持External的Shuffle Service,用户可以使用自定义的Shuffle。
- 从manager取得Writer,在这里获得的是HashShuffleWriter。
- 调用rdd开始运算,运算结果通过Writer进行持久化。由
ShuffleWriter.write实现。
writer通过获取下游Partiton的数量,这个Partiton的数量和Task的数量相对应。下游的每个Partiton都好对应于一个文件。每个文件会创建一个对应的DiskBlockObjectWriter,DiskBlockObjectWriter可以直接向一个文件写入数据,如果文件已经存在,那么会以追加的方式写入。
逻辑如下图所示:

存在的问题
每个Shuffle Map Task需要为每个下雨的Task创建一个单独的文件,文件数:
number(shuffle_map_task) * number(following_task)
生成环境中Task的数量实际上更多,因此这个简单的实现会带来以下问题:
- 每个节点可能会同时打开多个文件,每次打开文件都会占用一定内存。
- 从整体的角度看,打开多个文件对于系统来说意味着随机读,尤其是每个文件比较小但是数量非常多的情况。而现在机械硬盘在随机读方面的性能特别差,非常容易成为性能的瓶颈。
Shuffle Consolidate Writer
为了解决Shuffle过程产生文件过多的问题,加入Shuffle Consolidate Files机制。它的主要目标是减少Shuffle过程产生的文件。若使用这个功能,需要将spark.shuffle.consolidateFiles设置为true。
对于同一个Core的Shuffle Map Task,第一个Shuffle Map Task会创建一个文件;之后的就好将数据追加到这个文件上而不是新建一个文件。文件数量为:
number(cores) * number(following_task)
Sort Based Write
Hash Based Shuffle的每个mapper都需要为每个Reducer写一个文件,供Reducer读取,即需要产生M*R个数量的文件,如果Mapper和Reducer的数量比较大,产生的文件数会非常多。Spark1.1引入Sork Based Shuffle,首先每个Shuffle Map Task不会为每个Reducer生成一个单独的文件;相反,它会将所有的结果写到一个文件里,同时会生成一个Index文件,Reducer可以通过这个Index文件取得它需要处理的数据。
实现详解
Shuffle Map Task会安装Key对应的Partiton ID进行Sork,其中属于同一个Partition的key不会Sort。
对于需要Sort的运算,比如sortByKey,这个Sort是由Reducer完成的。
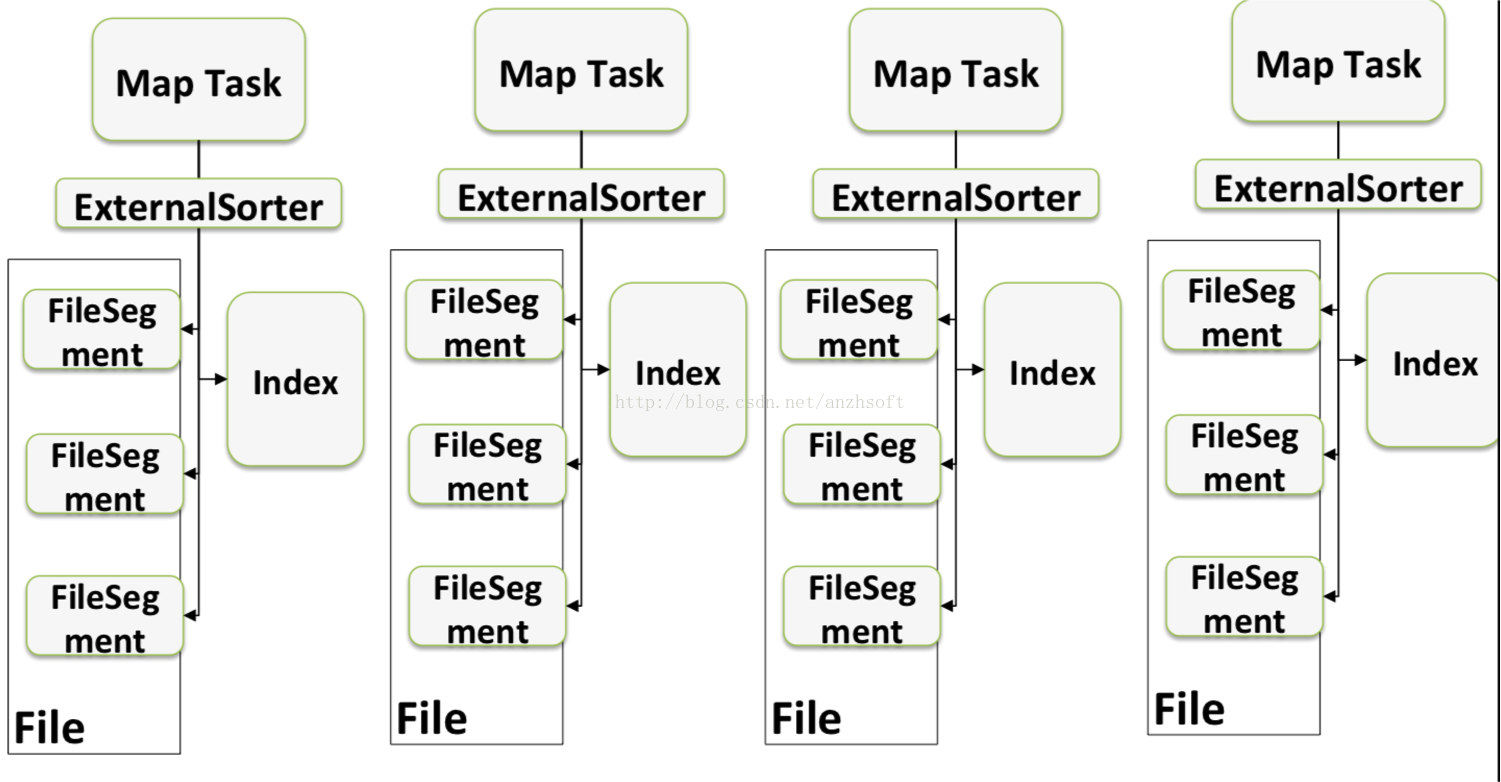
如果这个过程内存不够用了,那么这些已经拍好序的内容会被写入到外部存储。然后在结束的时候将这些不同的文件进行归并排序。
Shuffle Map Task运算结果的处理
Shuffle Map Task运算结果的处理分为两部分,一个是在Executor端直接处理Task结果的;另一个是Driver端在接到Task运行结束的消息时对Shuffle Write的结果进行处理。
Executor端的处理
在Executor运行Task时,将结果回传到Driver,会根据结果的大小使用不同的策略(上文有说明)。
Driver端的处理
TaskRunner将Task的执行状态汇报给Driver后,Driver会转给TaskSchedulerImpl#statusUpdate。在这里,不同的状态有不同的处理。
Shuffle Read
每个Stage的上边界,要么需要从外部存储读取数据,要么需要读取上一个Stage的输出;而下边界,要么是需要写入本地文件系统(需要Shuffle),以供child Stage读取,要么是最后一个Stage,需要输出结果。这里的Stage,在运行时就是可以以流水线的方式运行一组Task,除了最后一个Stage对应的是ResultTask,其余的Stage对应的都是Shuffle Map Task。
除了从外部存储读取数据,一般Task都是从ShuffledRDD的Shuffle Read开始的。
整体流程
Shuffle Read从org.apache.spark.rdd.ShuffledRDD#compute开始,通过调用ShuffleManager#getReader方法获得ShuffleManager,然后调用其read()方法进行读取。
/** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val wrappedStreams = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
serializerManager.wrapStream,
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue),
SparkEnv.get.conf.get(config.REDUCER_MAX_BLOCKS_IN_FLIGHT_PER_ADDRESS),
SparkEnv.get.conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM),
SparkEnv.get.conf.getBoolean("spark.shuffle.detectCorrupt", true))
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
val resultIter = dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data.
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// Use completion callback to stop sorter if task was finished/cancelled.
context.addTaskCompletionListener(_ => {
sorter.stop()
})
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
resultIter match {
case _: InterruptibleIterator[Product2[K, C]] => resultIter
case _ =>
// Use another interruptible iterator here to support task cancellation as aggregator
// or(and) sorter may have consumed previous interruptible iterator.
new InterruptibleIterator[Product2[K, C]](context, resultIter)
}
}